分表分页查询方案
解决问题:分表后,查询T表,N页(X=(N-1)*Y)的Y条数据
[ 参考文献 ] : https://cloud.tencent.com/developer/article/1048654
[ 参考文献 ] : https://cloud.tencent.com/developer/article/2202460
-- 分库分表前的查询语句
select * from T order by time limit Y offset X
方案一 全局视野法
- 将 order by time limit Y offset X,改写成 order by time limit X+Y offset 0 ;
- 假设共分为N个库,服务层将得到N*(X+Y)条数据:即例子中的6页数据;
- 服务层对得到的N*(X+Y)条数据进行内存排序,内存排序后再取偏移量X后的Y条记录,就是全局视野所需的一页数据。
优点
- sql修改简单,能够得到全局视野,业务精确无损。
缺点
- 每个分库都要进行查询;
- 每个分库都要返回更多的数据;
- 代码层面还要进行二次排序,增大了服务层的计算量;
- 随着页码的增大,返回数据增多,性能会急剧下降。
方案二 业务折衷-禁止跳页查询
- 产品不提供“直接跳到指定页面”的功能,而只提供“下一页”的功能。
- 将查询order by time offset X limit Y,改写成order by time where time > ${上一页的最大值} limit Y
方案三 业务折衷-允许精度丢失
- 假设查询100页后的100条数据,两个分片;
- 将 offset 10000 limit 100 改写为 offset 5000 limit 50;
- 每个分库偏移5000(一半),获取50条数据(半页);
- 得到的数据集进行合并,当然这一页数据并不是精准的。
方案四 二次查询法(终极方案)
假设查询200页后的5条数据,3个分片。
步骤一:查询改写
3个分片,改写为 select * from T order by time offset 333 limit 5,假设返回数据如下:
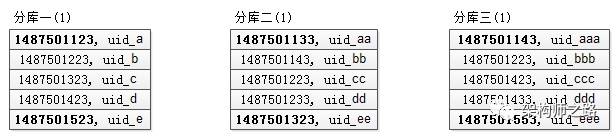
步骤二:找到返回全部数据的排序列最小值
定位到最小值是分库1的1487501123,这个过程只需要比较各个分库第一条数据,时间复杂度很低:
步骤三:查询二次改写
第二次要改写成一个between语句,between起点是time_min,between的终点是各分库返回数据的最大值:
-- 全局最小值1487501123
-- 第一个分库,第一次返回数据的最大值是 1487501523
select * from T order by time where time between 1487501123 and 1487501523;
-- 第二个分库,第一次返回数据的最大值是 1487501323
select * from T order by time where time between 1487501123 and 1487501323;
-- 第三个分库,第一次返回数据的最大值是 1487501553
select * from T order by time where time between 1487501123 and 1487501553;
相对第一次查询,第二次查询返回比第一次查询结果集更多的数据,假设三个分库返回的数据如下(粉底为多返回的数据):

可以看到:
分库一:由于time_min来自原分库一,所以分库一的返回结果集和第一次查询相同;
分库二:头部的1条记录(time最小的记录)是新的(上图中粉色记录);
分库三:头部的2条记录(time最小的2条记录)是新的(上图中粉色记录)。
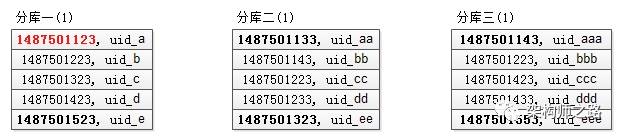
步骤四:找到time_min在全局的offset

在每个结果集中虚拟一个time_min记录节点(红字):
分库一:time_min在第一个库的offset是333;
分库二:1487501133的offset是333(根据第一次查询条件得出的),故倒推虚拟time_min在第二个库的offset是331;
分库三:1487501143的offset是333(根据第一次查询条件得出的),故倒推虚拟time_min在第三个库的offset是330。
综上,time_min在全局的offset是333+331+330=994。
步骤五:得到了time_min在全局的offset,根据二次查询结果,得出全局offset 1000 limit 5的记录
time_min的全局offset是994,去除合并后前7条数据(offset + 6 = 1000,994自己算一条),得出结果集(黄底数据)

优点
精确的返回业务所需数据,每不会随着翻页增加数据的返回量;
缺点
需要进行两次数据库查询。