缓存一致性解决方案
实际项目中,在一些QPS比较高的场景下,经常引入缓存来缓解数据库的查询压力,以缓存的空间来换取查询效率的提升。但是一旦引入了缓存,就一定会遇到缓存中的数据与数据库中的数据如何保持一致的问题,本文就是针对两者之间的数据一致性问题进行分析。
[参考文献] : https://mp.weixin.qq.com/s/nqyQZxuprbSHvx_IoNtTeA
先写数据库再写缓存
由于引入了Redis缓存,数据会保存在数据库以及Redis中,这就带来了另一个头痛的问题,如何保证两边的数据一致性,到底是先更新数据库还是先更新Redis缓存呢?增加缓存之后由于涉及到数据库和Redis两边的数据写入时机问题,当进行业务数据写入的时候,如果先写入数据库再写入Redis缓存,那么就会出现这样的问题,
如果数据库写入成功,而Redis写入失败,那么数据库中就是最新值,缓存中为旧值,出现数据不一致,如果此时查询数据的时候就会查询到旧值,从而导致业务数据异常。
先写缓存再写数据库
另外一种方案,如果先更新Redis再更新数据库,但是Redis缓存更新成功了,数据库更新失败了,那么就说明缓存中为业务最新值,而数据库中是业务旧值,那么此时进行数据查询的时候服务可以获取到最新值,但是过一段时间缓存失效之后,又会从数据库中获取到旧值,又会出现数据不一致的情况。
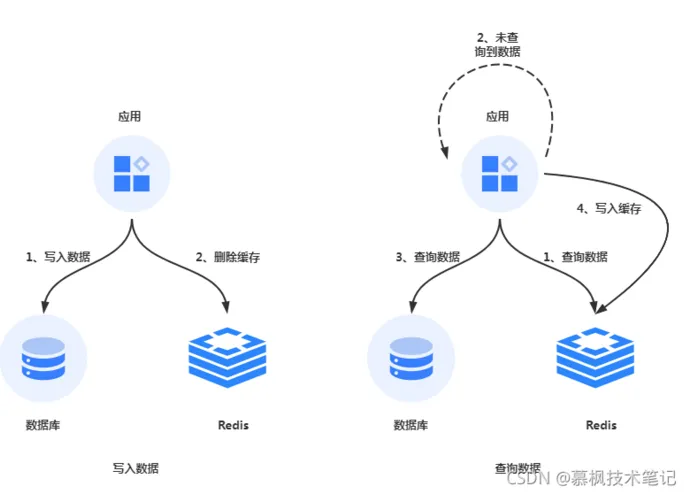
Cache Aside Pattern
这是比较经典的解决方案,总的来说就是在数据查询的时候:
(1)先查询缓存,如果缓存中有数据的话直接返回缓存中的数据;
(2)如果缓存中没有数据,则从数据库中进行数据获取,而后再将查询到的数据更新到缓存中;
(3)在进行数据数据更新的时候,先更新数据库,再删除缓存;
这个方案比较特殊的部分就是在于更新数据的时候主动删除缓存,一般情况下都是更新完数据库再更新缓存。那为什么这个方案中却主动删除缓存呢?其实我觉得这是种小聪明的偷懒行为,为什么这么说,因为缓存中的数据实际上有的不仅仅是数据库表中某个字段的值,而是多个数据计算之后的值,另外如果这些缓存被访问的频率不是很高的话,如果每次更新数据库的时候都要进行缓存,那就有点资源浪费了。因此通过这种删除缓存的方法,同时复用了无缓存从数据坤获取数据后更新缓存的流程,实际也是一种懒加载的思想。
如何保证第二步骤执行成功?
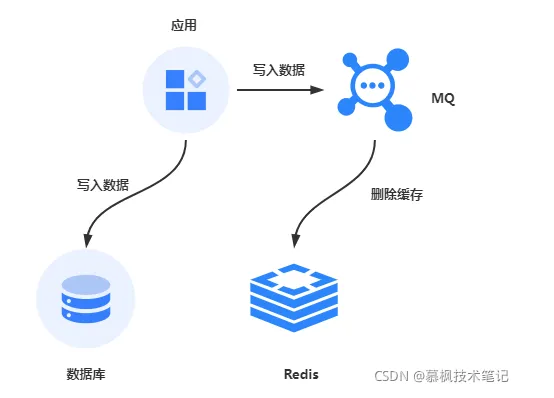
正如前文所说的,无论是新更新缓存还是先删除缓存,都涉及到如何让第二步骤的执行保证成功,最直接的办法就是实现重试。但是重试也不是说说这么简单的,重试也可能还是失败,重试的次数到底怎么控制重试多少次才合理呢?另外如果一直重试的话,线程无法响应客户端请求也是个问题。因此比较好的处理方法就是实现异步重试。我们可以将重试的请求放到一个消息队列中,让消费者去干这个事情。
不过还有一个值得注意的问题,就是在设置缓存的时候,需要设置缓存对应的过期时间。为什么这么说呢?因为对于缓存来说,实际上有个命中率的问题,并不是在缓存中的数据都是被高频率访问的,有的数据命中率实际并不高,因此通过设置缓存的过期时间可以提高Redis的内存使用效率。另外其实设置缓存也是一种兜底的策略,就是当数据出现不一致的情况时,至少有个过期时间可以让缓存中的数据失效,从而从数据库中重新获取最新的数据来更新缓存。
缓存的最初的目的是什么
这一路看上去似乎方案都不是很完美,我们能做到严格的强一致性么?做到是可以做到,但是不容易,为了保证数据一致性付出的代价也会很大。所以我们回到引入缓存的最初的目的到底是什么,是为了提升平台的性能,但是如果为了数据的强一致反而降低了性能,是不是一种画虎不成反类犬的感觉。
因此既然我们引入了缓存,就需要在一定程度上去容忍数据一致性的问题。但是同时我们需要有一定的措施来提升健壮性,比如增加重试机制,比如设置缓存失效时间来进行数据兜底,从而达到数据的最终一致。性能和一致性就像鱼和熊掌,虽然我们都爱,但是总要有取舍,总要有平衡。